시스템 I/O 완전 정복: 파일, 네트워크, 시그널의 동작 원리💻🌐
시스템 프로그래밍의 여정에서 입출력(I/O)은 마치 건물의 기초와 같다. 우리가 만드는 프로그램이 외부 세계와 소통하고, 커널의 서비스를 이용하는 거의 모든 작업이 I/O를 통해 이루어지기 때문이다. 지난 시간까지 컴파일, 링킹, 로딩, 그리고 라이브러리에 관해 살펴봤다면, 이제는 프로그램이 실제로 어떻게 파일 시스템에 접근하고, 네트워크 너머의 다른 시스템과 대화하며, 예기치 않은 이벤트(시그널)에 대응하는지 그 동작 원리를 low-level에서 분석해 볼 차례다. 이번 포스팅에서는 Unix 시스템의 파일 I/O, 네트워크 소켓 I/O, 그리고 비동기 이벤트 처리의 핵심인 시그널에 대해 깊이 있게 탐구하고자 한다. 특히 모든 시스템 콜 호출 후에는 반드시 반환 값을 확인하고 오류를 적절히 처리하는 습관이 중요하다는 것을 미리 강조하고 싶다.
1. Unix 파일 시스템과 I/O 기본기: 모든 것은 파일이다! 📂
Unix 철학의 핵심 중 하나는 "모든 것을 파일로 취급한다"는 것이다. 우리가 흔히 생각하는 일반 파일(텍스트, 이미지, 실행 파일 등)뿐만 아니라, 디렉터리, 하드 디스크 같은 블록 디바이스(/dev/sda), 키보드나 터미널 같은 캐릭터 디바이스(/dev/tty), 심지어 실행 중인 프로세스 정보를 담고 있는 /proc 같은 가상 파일 시스템까지 모두 일관된 파일 인터페이스를 통해 접근할 수 있다. 이러한 접근을 가능하게 하는 것이 바로 로우레벨 파일 I/O 시스템 콜들이다.
 |
| Unix File Types |
-
open(const char *path, int flags, ...): 지정된path의 파일을 열고, 해당 파일에 접근할 수 있는 파일 디스크립터(file descriptor, fd)를 반환한다. 파일 디스크립터는 커널이 특정 파일을 식별하기 위해 사용하는 작은 음이 아닌 정수 값이다.flags인자에는O_RDONLY(읽기 전용),O_WRONLY(쓰기 전용),O_RDWR(읽기/쓰기),O_CREAT(없으면 생성),O_APPEND(항상 파일 끝에 추가),O_TRUNC(열 때 파일 내용 모두 삭제) 등을 조합하여 사용한다.- 원자적 연산:
O_CREAT와O_EXCL플래그를 함께 사용하면, 파일이 이미 존재할 경우open()이 실패하므로 파일 생성의 원자성(atomicity)을 보장할 수 있다. 이는 주로 락(lock) 파일을 만들 때 유용하다.O_APPEND플래그는 여러 프로세스가 동시에 파일에 쓸 때 각 write가 항상 파일의 현재 끝에서 시작하도록 보장한다. - 오류 발생 시
-1을 반환하고errno전역 변수에 오류 코드가 설정된다. 이때perror("open failed")와 같이 오류 메시지를 출력하고exit(1)등으로 프로그램을 종료하는 것이 일반적인 오류 처리 방식이다. - 예:
fd = open("/etc/hosts", O_RDONLY);Opening Files
- 원자적 연산:
-
close(int fd): 사용이 끝난 파일 디스크립터fd를 닫는다. 성공 시0, 실패 시-1을 반환한다. 열었던 파일은 반드시 닫아주어야 시스템 자원 누수를 막을 수 있다.Closing Files
-
read(int fd, void *buf, size_t count): 파일 디스크립터fd가 가리키는 파일에서 최대count바이트만큼 데이터를 읽어buf버퍼에 저장한다. 실제로 읽은 바이트 수를 반환하며, 파일의 끝(EOF)에 도달하면0을 반환하고, 오류 발생 시-1을 반환한다. 요청한count보다 적은 바이트가 읽히는 것(short read)은 정상적인 상황일 수 있다 (예: 파일 끝에 가까워졌거나, 파이프에서 데이터가 아직 덜 왔을 때).Reading Files write(int fd, const void *buf, size_t count):buf버퍼에 있는 데이터 중 최대count바이트를 파일 디스크립터fd가 가리키는 파일에 쓴다. 실제로 쓴 바이트 수를 반환하며, 오류 발생 시-1을 반환한다.read와 마찬가지로 요청한count보다 적은 바이트가 쓰이는 것(short write)도 가능하다.Writing Files lseek(int fd, off_t offset, int whence): 파일 디스크립터fd에 대한 현재 파일 위치(current file position 또는 offset)를 명시적으로 변경한다. 파일은 바이트들의 순차적인 나열(B0,B1,...,Bk−1,Bk,Bk+1,...)로 간주되며, 현재 파일 위치 k는 다음read()나write()작업이 시작될 파일 내 오프셋을 나타낸다.-
whence인자에는SEEK_SET(파일 시작 기준offset),SEEK_CUR(현재 위치 기준offset),SEEK_END(파일 끝 기준offset)를 사용한다.- 성공 시 새로운 파일 오프셋을, 실패 시
-1을 반환한다.
Seeking Files
-
파일 메타데이터 접근: stat(), fstat(), lstat()
커널은 파일의 내용뿐 아니라 파일의 종류, 크기, 권한, 소유자, 최종 수정 시간 등 다양한 메타데이터(metadata)도 관리한다. 이러한 정보는 stat 구조체를 통해 얻을 수 있으며, stat(const char *path, struct stat *buf), fstat(int fd, struct stat *buf), lstat(const char *path, struct stat *buf) 시스템 콜을 사용한다. (lstat은 심볼릭 링크 자체의 정보를 가져온다.) 이 정보는 v-node 테이블(아래 설명)에 저장된 내용의 일부이다.
-
중요: 모든 시스템 콜과 오류 처리!
위에 언급된 모든 시스템 콜(및 앞으로 나올 시스템 콜들)은 성공 또는 실패를 나타내는 값을 반환한다. 실패 시에는 보통 -1이 반환되고, 전역 변수 errno에 특정 오류 코드가 설정된다. perror() 함수는 errno 값에 해당하는 시스템 오류 메시지를 표준 에러로 출력해주므로 디버깅에 매우 유용하다. 시스템 프로그래밍에서는 모든 시스템 콜의 반환 값을 철저히 확인하고 적절히 오류를 처리하는 것이 프로그램의 안정성을 보장하는 기본 중의 기본이다.





2. 커널 내부 파일 관리: 테이블 3총사 (Descriptor, Open File, v-node) 🗂️
Unix 커널이 열린 파일을 효율적으로 관리하고 파일 공유를 가능하게 하기 위해 사용하는 핵심 데이터 구조는 다음과 같다.
 |
| How to the Unix Kernel Represents Open Files |
-
파일 디스크립터 테이블 (Descriptor Table):
- 각 프로세스마다 독립적으로 존재한다.
- 프로세스가 파일을
open()할 때마다 이 테이블의 비어있는 항목(가장 작은 사용 가능한 정수 인덱스, 즉 파일 디스크립터)이 할당된다. - 테이블의 각 항목은 열린 파일 테이블(Open File Table)의 특정 항목을 가리키는 포인터(또는 인덱스) 역할을 한다.
- 기본적으로 모든 프로세스는 시작 시 표준 입력(stdin, fd 0), 표준 출력(stdout, fd 1), 표준 에러(stderr, fd 2)에 해당하는 파일 디스크립터를 할당받는다.
-
열린 파일 테이블 (Open File Table):
- 시스템 전체에서 모든 프로세스가 공유한다.
- 프로세스가
open()시스템 콜을 호출하면, 커널은 이 테이블에 새로운 항목을 생성한다 (단, 해당 파일이 다른 프로세스에 의해 이미 열려 특정 v-node를 사용 중이라도,open()호출마다 고유한 열린 파일 테이블 항목이 생성될 수 있다. 파일 공유는 주로fork나dup2를 통해 같은 열린 파일 테이블 항목을 여러 디스크립터가 가리킬 때 발생). - 각 항목은 다음 정보를 포함한다:
- 현재 파일 위치 (File Position/Offset):
read(),write()작업 시 사용될 파일 내 오프셋. 이 위치는 읽거나 쓸 때마다 자동으로 갱신된다. - 참조 카운트 (Reference Count,
refcnt): 얼마나 많은 파일 디스크립터 테이블 항목이 이 열린 파일 테이블 항목을 가리키고 있는지를 나타낸다.refcnt가 0이 되면 이 항목은 테이블에서 제거된다. - 파일 접근 모드 (File Access Mode): 파일을 열 때 지정한 접근 모드 (읽기 전용, 쓰기 전용 등).
- v-node 테이블 포인터: 실제 파일 정보를 담고 있는 v-node 테이블의 해당 항목을 가리킨다.
- 현재 파일 위치 (File Position/Offset):
-
v-node 테이블 (v-node Table):
- 시스템 전체에서 모든 프로세스가 공유한다.
- 파일 시스템에 존재하는 모든 파일과 디렉터리는 이 테이블의 항목(v-node)을 통해 표현된다. 디스크 상의 i-node와 유사한 개념이지만, 파일 시스템 종류에 독립적인 인터페이스를 제공한다.
- 각 항목은 파일의 메타데이터를 포함한다:
- 파일 타입 (일반 파일, 디렉터리, 소켓, 심볼릭 링크 등)
- 파일 크기
- 파일 접근 권한 (owner, group, others)
- 파일 소유자 ID, 그룹 ID
- 타임스탬프 (생성, 접근, 수정 시간)
- 실제 데이터 블록을 가리키는 포인터 등 (파일 시스템에 따라 다름)
- 열린 파일 테이블의 각 항목은 이 v-node 테이블의 특정 항목을 가리킨다. 즉, 하나의 파일(v-node)이 여러 번
open()될 수 있으며, 각각 다른 열린 파일 테이블 항목을 통해 접근될 수 있다 (이 경우 파일 위치는 독립적).
파일 공유 (File Sharing) 는 주로 다음 두 가지 상황에서 발생한다:
fork()호출: 자식 프로세스는 부모 프로세스의 파일 디스크립터 테이블을 복사한다. 이로 인해 부모와 자식은 동일한 열린 파일 테이블 항목들을 가리키게 되며, 따라서 동일한 파일 위치(file position)를 공유하게 된다. (엄밀히는 파일 디스크립터 테이블이 복사되지만, 각 엔트리가 가리키는 열린 파일 테이블 엔트리의 주소값이 복사되어 공유가 이루어지는 것이다.)dup2()또는 여러open()호출: 여러 파일 디스크립터가 (예를 들어dup2를 통해 또는 같은 파일을 여러 번open하여 각기 다른 열린 파일 테이블 엔트리가 같은 v-node를 가리키도록 하여) 결과적으로 같은 파일 내용을 공유하게 된다. 만약 여러 디스크립터가 정확히 같은 열린 파일 테이블 엔트리를 공유한다면 (주로fork나dup2의 경우), 파일 위치도 공유된다.
 |
| File Sharing |
3. I/O 리디렉션의 마법: dup2() 시스템 콜 🪄
쉘에서 자주 사용하는 I/O 리디렉션 (예: ls > foo.txt 또는 wc < bar.txt)은 특정 파일 디스크립터가 가리키는 대상을 변경하는 메커니즘이다. 이는 내부적으로 dup2(int oldfd, int newfd) 시스템 콜을 통해 구현될 수 있다.
 |
| How does a shell implement I/O redirection? |
dup2(oldfd, newfd):newfd가 이미 열려 있는 파일 디스크립터라면, 커널은 먼저newfd를 조용히 닫는다 (마치close(newfd)를 호출한 것처럼).
- 그 후,
newfd가oldfd와 동일한 열린 파일 테이블 항목을 가리키도록 설정한다. - 결과적으로
newfd는oldfd의 복제본이 되며, 해당 열린 파일 테이블 항목의 참조 카운트(refcnt)는 증가한다.
- 예를 들어,
fd = open("foo.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);로foo.txt를 쓰기 모드로 열고 파일 디스크립터fd를 얻었다고 하자. 그 다음dup2(fd, STDOUT_FILENO);(여기서STDOUT_FILENO는 1)를 호출하면, 표준 출력(fd 1)이 원래 가리키던 터미널 대신foo.txt파일을 가리키게 된다. 이제부터printf등으로 표준 출력에 쓰는 모든 내용은foo.txt에 기록된다.fd는 닫아도STDOUT_FILENO는 여전히foo.txt를 가리킨다.


주어진 ffiles1.c 예제에서 dup2(fd2, fd3) 호출 후 read(fd2, ...)와 read(fd3, ...)를 수행하면, 두 read 호출이 동일한 파일 오프셋에서 시작하여 다음 바이트를 순차적으로 읽는 것을 볼 수 있다. 이는 fd2와 fd3가 동일한 열린 파일 테이블 항목(따라서 동일한 파일 위치)을 공유하기 때문이다.
 |
| ffiles1.c |
4. 표준 I/O vs. Unix I/O: 버퍼링의 세계와 선택의 기준 🆚
C 언어는 <stdio.h> 헤더 파일을 통해 표준 I/O (Standard I/O) 라이브러리 함수들을 제공한다. 이 함수들은 앞에서 설명한 open, read, write, close와 같은 Unix I/O (System Calls)를 내부적으로 사용하여 구현된다. 둘 사이의 가장 큰 차이점은 버퍼링(buffering)이다.
-
Unix I/O (시스템 콜):
open,read,write,close등.- 운영체제 커널에 직접 요청하는 저수준 함수이다.
- 기본적으로 커널 레벨에서 최소한의 버퍼링만 수행하거나, 직접적인 I/O에 가깝다 (예: 디스크 I/O 시 커널의 페이지 캐시). 사용자 공간에서의 추가적인 버퍼링은 없다.
- 파일 디스크립터(작은 정수
int)를 사용한다.
-
표준 I/O (라이브러리 함수):
fopen,fread,fwrite,fprintf,fgets,fclose등.- C 라이브러리 수준에서 제공되며, 내부적으로 Unix I/O 시스템 콜을 호출한다.
- 사용자 공간(user space)에서 자체적인 버퍼링을 수행하여 I/O 효율을 높이려 한다. 데이터를 모았다가 한 번에 시스템 콜을 호출함으로써 시스템 콜 호출 횟수를 줄인다.
FILE *포인터 (스트림)를 사용한다.fflush(FILE *stream)함수는 해당 스트림의 버퍼에 남아있는 내용을 강제로 쓰도록 (flush) 한다.fclose()는 자동으로 flush를 수행한다.Buffering in Standard I/O
-
버퍼링의 종류:
- 완전 버퍼링 (Fully Buffered): 버퍼가 가득 찼을 때만 실제 I/O 작업이 일어난다. 디스크 파일을 대상으로 하는 스트림의 기본 방식이다.
- 줄 단위 버퍼링 (Line Buffered): 개행 문자(
\n)를 만날 때마다, 또는 버퍼가 가득 차거나 입력 요청 시 실제 I/O가 일어난다. 터미널에 연결된stdin과stdout의 기본 방식이다. - 버퍼링 없음 (Unbuffered): 데이터가 즉시 전달된다.
stderr의 기본 방식이며, 오류 메시지가 지체 없이 출력되도록 하기 위함이다.setbuf()나setvbuf()함수로 버퍼링 방식을 변경할 수 있다.
-
언제 무엇을 사용할까?
- 표준 I/O는 사용하기 편리하고, 버퍼링 덕분에 문자 단위나 줄 단위 I/O에서 성능상 이점이 있을 수 있다. 대부분의 일반적인 파일 처리 작업에 적합하다.
- Unix I/O는 더 세밀한 제어가 필요하거나(예: non-blocking I/O, 파일 디스크립터 직접 조작), 바이너리 데이터를 다루거나, 버퍼링으로 인한 지연을 피하고 싶을 때 사용한다. 네트워크 프로그래밍이나 시스템 유틸리티 개발 시 더 선호될 수 있다.
fdopen(int fd, const char *mode)함수를 사용하면 이미 열린 파일 디스크립터fd로부터 표준 I/O 스트림(FILE *)을 생성할 수 있다. 반대로fileno(FILE *stream)함수는 표준 I/O 스트림으로부터 해당 파일 디스크립터를 얻을 수 있다.- 주의: 하나의 파일에 대해 Unix I/O와 표준 I/O를 혼용하는 것은 버퍼링 문제로 인해 예기치 않은 동작을 유발할 수 있으므로 신중해야 한다.

5. 네트워크 I/O: 소켓(Socket) 인터페이스로 세상과 통신하기 🌍
네트워크 통신 역시 Unix의 "모든 것은 파일" 철학을 확장하여 파일 I/O와 유사한 추상화 모델을 사용한다. 소켓(Socket) 인터페이스가 바로 그것이며, 네트워크 통신의 양 끝점(endpoint)을 나타내는 파일 디스크립터로 다뤄진다. 주로 클라이언트-서버 모델에서 사용된다.
 |
| Sockets Interface |
네트워크 통신 설정 과정은 일반적으로 다음과 같다. (TCP/IP 기준)
 |
| Overview of Network I/O |
-
주소 정보 획득:
getaddrinfo()getaddrinfo(const char *node, const char *service, const struct addrinfo *hints, struct addrinfo **res)함수는 호스트 이름(node, 예: "www.google.com service, 예: "http" 또는 "80")를 입력으로 받아, 소켓 생성 및 연결/바인딩에 필요한 주소 정보를 담은struct addrinfo구조체의 연결 리스트를res에 반환한다.Linked List Returned by getaddrinfo hints는 원하는 소켓 타입 (예:AF_INETfor IPv4,SOCK_STREAMfor TCP) 등을 지정하는 데 사용된다.- 성공 시 0, 실패 시 non-zero 오류 코드를 반환한다.
gai_strerror()로 오류 메시지를 얻을 수 있다. - 사용 후에는
freeaddrinfo(res)로 할당된 메모리를 반드시 해제해야 한다.getaddrinfo
-
소켓 생성:
socket()socket(int domain, int type, int protocol)시스템 콜은 통신을 위한 소켓을 생성하고 파일 디스크립터를 반환한다.domain: 주소 체계 (예:AF_INET(IPv4),AF_INET6(IPv6)).type: 소켓 타입 (예:SOCK_STREAM(TCP, 신뢰성 있는 연결 지향 스트림),SOCK_DGRAM(UDP, 비연결 지향 데이터그램)).protocol: 특정 프로토콜 (보통 0을 주면domain과type에 맞는 기본 프로토콜 자동 선택).getaddrinfo()가 반환한addrinfo구조체의ai_family,ai_socktype,ai_protocol필드를 여기에 그대로 사용하면 된다.socket
-
서버 측 설정:
bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen): 생성된 소켓sockfd를 특정 로컬 IP 주소와 포트 번호에 할당(바인딩)한다.getaddrinfo()로 얻은addrinfo구조체의ai_addr(실제 주소 정보)와ai_addrlen(주소 길이)을 사용한다.bind listen(int sockfd, int backlog): 서버 소켓sockfd가 클라이언트로부터 연결 요청을 받을 수 있도록 "수신 대기(listening)" 상태로 만든다.backlog는 아직accept되지 않은 연결 요청들이 대기할 수 있는 큐의 최대 크기를 지정한다.listen accept(int listenfd, struct sockaddr *addr, socklen_t *addrlen):listenfd소켓으로 들어오는 첫 번째 연결 요청을 큐에서 꺼내 수락한다.- 이 호출은 새로운 연결 요청이 들어올 때까지 블로킹(blocking)된다 (기본적으로).
- 연결이 수락되면, 해당 클라이언트와의 통신에 사용될 새로운 연결된 소켓(connected socket) 디스크립터를 반환한다.
- 선택적으로,
addr과addrlen인자를 통해 연결된 클라이언트의 주소 정보를 얻을 수 있다. - 원래의 리스닝 소켓
listenfd는 닫히지 않고 계속해서 다른 클라이언트들의 연결 요청을 받을 수 있다. 실제 데이터 송수신은accept가 반환한 새로운 소켓 디스크립터를 통해 이루어진다.accept
-
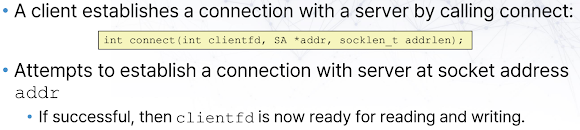
클라이언트 측 설정:
connect(int clientfd, const struct sockaddr *addr, socklen_t addrlen):clientfd소켓을 사용하여addr로 지정된 서버 주소 및 포트에 연결을 시도한다. 서버가 해당 포트에서listen중이고accept호출을 통해 이 요청을 수락하면 연결이 성립된다. 이 호출 또한 연결이 성공하거나 실패할 때까지 블로킹될 수 있다.connect
-
데이터 통신:
- 연결이 성립된 후 (TCP의 경우) 또는 소켓이 생성된 후 (UDP의 경우, 주소 지정 필요),
send(int sockfd, const void *buf, size_t len, int flags)와recv(int sockfd, void *buf, size_t len, int flags)함수, 또는 일반적인 파일 I/O 함수인read()와write()를 사용하여 데이터를 주고받는다.send & recv
- 연결이 성립된 후 (TCP의 경우) 또는 소켓이 생성된 후 (UDP의 경우, 주소 지정 필요),
-
연결 종료:
close(int sockfd)함수를 사용하여 소켓 파일 디스크립터를 닫고 연결을 종료한다. TCP 연결의 경우, 내부적으로 적절한 연결 종료 절차(예: 4-way handshake)가 진행된다.







6. 시그널(Signal): 비동기 이벤트 처리의 달인 🚦
시그널(Signal)은 프로세스에게 특정 이벤트가 발생했음을 비동기적으로 알리는 소프트웨어 인터럽트 메커니즘이다. 하드웨어 인터럽트가 CPU에게 알리듯, 시그널은 커널이 프로세스에게 알린다.
 |
| Signal |
-
시그널 발생 원인:
- 다른 프로세스가
kill()시스템 콜을 사용하거나, 쉘에서/bin/kill명령을 실행하여 명시적으로 시그널을 보낼 때. - 키보드 입력: 터미널에서 특정 키 조합 (예:
Ctrl-C는SIGINT시그널을,Ctrl-Z는SIGTSTP시그널을 현재 포어그라운드 프로세스 그룹에 보냄).Signal from the Keyboard - 하드웨어 예외: 잘못된 메모리 접근 (
SIGSEGV), 0으로 나누기 (SIGFPE) 등. - 커널이 프로세스에게 특정 이벤트 발생을 알릴 때: 자식 프로세스 종료 (
SIGCHLD), 알람 타이머 만료 (SIGALRM) 등.Sending Signal
- 다른 프로세스가
-
프로세스 그룹 (Process Group):
- 하나 이상의 관련된 프로세스들의 모음이다. 각 프로세스 그룹은 고유한 프로세스 그룹 ID (PGID)를 가진다.
- 시그널은 특정 프로세스 ID(PID)뿐만 아니라 특정 프로세스 그룹 ID(PGID)에도 보낼 수 있다. 예를 들어,
/bin/kill -9 -24817명령어는 PGID가 24817인 모든 프로세스에게SIGKILL시그널을 보낸다 (PGID 앞에 음수 부호)./bin/kill getpgrp()는 현재 프로세스의 PGID를 반환하고,setpgid(pid_t pid, pid_t pgid)는 특정 프로세스(pid)의 PGID를pgid로 변경한다.Process Groups
-
시그널 수신 시 프로세스의 기본 동작:
시그널을 받은 프로세스는 해당 시그널에 대해 다음 중 하나의 기본 동작을 수행할 수 있다 (시그널 종류마다 기본 동작이 다름):
- 무시 (Ignore): 시그널을 아무런 처리 없이 무시한다. (단,
SIGKILL과SIGSTOP은 무시하거나 잡을 수 없다.) - 종료 (Terminate): 프로세스가 즉시 종료된다. 많은 시그널의 기본 동작이다 (예:
SIGINT,SIGTERM). - 코어 덤프와 함께 종료 (Terminate with core dump): 프로세스의 메모리 상태를
core파일로 저장하고 종료한다. 디버깅에 사용된다 (예:SIGQUIT,SIGSEGV). - 중단 (Stop): 프로세스 실행이 일시 중지된다 (예:
SIGTSTP,SIGSTOP의 기본 동작). - 계속 (Continue): 중단된 프로세스가 다시 실행을 계속한다 (예:
SIGCONT의 기본 동작).





-
시그널 핸들러 (Signal Handler) 설치:
프로세스는 시그널 핸들러라는 사용자 정의 함수를 설치하여 특정 시그널에 대한 기본 동작을 변경하고 원하는 작업을 수행하도록 할 수 있다.
external.c (react to externally generated events) internal.c (react to internally generated events)
signal(int signum, sighandler_t handler)함수는 시그널signum에 대해handler함수를 실행하도록 설정한다.handler는void (*sighandler_t)(int)형태의 함수 포인터이다.handler로SIG_IGN을 지정하면 해당 시그널을 무시하고,SIG_DFL을 지정하면 기본 동작을 수행하도록 한다.
- 모던 C에서 활용되는 시그널 처리 함수는
sigaction()이다.sigaction()은 시그널 처리 중 다른 시그널의 블로킹 여부 등 더 세밀한 제어를 제공하므로, 새로운 코드에서는signal()보다sigaction()사용이 권장된다. - 주어진
external.c와internal.c예제는 각각SIGINT와SIGALRM시그널 핸들러의 작동 방식을 보여주며,fork13()예제는 자식 프로세스에서SIGINT시그널 핸들러를 설치하여 부모가 보낸SIGINT에 반응하도록 하는 것을 보여준다.


 |
| fork13() - Signal Handling Example |
-
시그널 마스크 (Signal Mask)와 Pending 시그널:
- 각 프로세스는 시그널 마스크를 가지고 있으며, 이는 현재 블록(block)되어 있는 시그널들의 집합이다. 블록된 시그널은 핸들러에게 전달되지 않고 pending 상태로 대기한다. 해당 시그널이 언블록(unblock)되면 그제야 전달된다.
sigprocmask()함수를 사용하여 시그널 마스크를 조회하거나 변경할 수 있다.- 시그널은 생성 (generated) -> (블록되지 않았다면) 전달 (delivered) / (블록되었다면) pending 상태를 거친다.
 |
| Pending Signal |
 |
| Overview of Signal mechanism |
-
시그널 핸들러 작성 시 주의사항: 비동기-시그널 안전성 (Async-Signal Safety) ⚠️
시그널 핸들러는 프로그램의 일반적인 실행 흐름과 관계없이 아무 때나 호출될 수 있는 비동기적 코드이다. 따라서 핸들러 내에서 호출할 수 있는 함수는 제한적이다. 비동기-시그널 안전(async-signal-safe)하다고 알려진 함수들만 사용해야 한다.
- 안전하지 않은 함수를 호출하면 전역 데이터 구조가 깨지거나, 교착 상태(deadlock)에 빠지는 등의 문제가 발생할 수 있다.
- 예를 들어, 대부분의 표준 I/O 함수 (
printf등),malloc,free등은 안전하지 않다. - 안전한 함수의 예로는
_exit(),write()(파일 디스크립터에 직접 쓰는 경우),read(),close(),kill(),getpid(),sigprocmask()등이 있다. (자세한 목록은man 7 signal-safety참조) - 시그널 핸들러는 가능한 한 짧고 빠르게 작업을 마치고 반환해야 한다. 복잡한 작업은 핸들러 내에서 플래그만 설정하고, 주 프로그램 루프에서 해당 플래그를 확인하여 처리하는 것이 일반적이다.
-
SIGCHLD시그널과 자식 프로세스 관리 (좀비 프로세스 방지): - 자식 프로세스가 종료되거나 중단되면, 커널은 부모 프로세스에게
SIGCHLD시그널을 보낸다. - 부모 프로세스는 이 시그널을 받으면
wait()또는waitpid()시스템 콜을 호출하여 자식의 종료 상태를 수집하고, 자식 프로세스와 관련된 커널 자료구조를 정리해야 한다. - 이를 제대로 처리하지 않으면 종료된 자식 프로세스는 시스템에 좀비 프로세스(zombie process)로 남게 되어 시스템 자원을 불필요하게 소모한다. 따라서
SIGCHLD핸들러 내에서waitpid()를 루프를 돌며 호출하여 종료된 모든 자식을 처리하는 것이 일반적인 패턴이다. (자세한 내용은 다음 글에서 다뤄보도록 하겠다)
결론: lew-level I/O와 시그널, Unix 시스템의 메커니즘을 이해하다
지금까지 Unix 시스템에서 파일 I/O, 네트워크 소켓 I/O, 그리고 시그널이 로우레벨에서 어떻게 동작하는지 그 원리를 깊이 있게 살펴보았다. 파일 디스크립터부터 커널 내부의 복잡한 테이블들, 소켓 통신의 단계별 과정, 그리고 예측 불가능한 시점에 발생하는 시그널을 다루는 정교한 메커니즘까지, 이 모든 것이 우리가 매일 사용하는 시스템을 안정적이고 효율적으로 움직이게 하는 핵심 요소들이다.
이러한 로우레벨 메커니즘에 대한 깊이 있는 이해는 단순히 코드를 작성하는 것을 넘어, 복잡한 시스템의 동작을 분석하고, 성능 병목 지점을 찾아내며, 예측 불가능한 오류에도 강인한 프로그램을 만드는 데 강력한 기반이 될 것이다. 시스템 프로그래밍의 길은 알면 알수록 새롭고 도전적인 과제들로 가득하지만, 그만큼 매력적인 분야임에 틀림없다.
