Active Learning: 제한된 라벨링 예산으로 모델 성능 극대화하기 – 핵심 원리와 쿼리 전략 심층 탐구 💡
지난번에는 레이블이 부족한 데이터를 활용하는(라벨링 완료) Semi-Supervised Learning (준지도 학습)에 대해 알아보았다. 데이터를 효율적으로 활용하려는 노력은 머신러닝 분야의 중요한 화두임에 틀림없다. 이번에는 한정된 '라벨링 예산'이라는 현실적인 제약 하에서(라벨링 전) 모델의 성능을 최대한 끌어올리는 전략인 Active Learning (액티브 러닝)에 대해 깊이 있게 탐구해보고자 한다.
오늘날 웹 페이지, 이미지, 단백질 서열 등 방대한 양의 데이터가 쏟아지고 있지만, 이 모든 데이터에 전문가가 직접 라벨을 다는 것은 시간과 비용 측면에서 거의 불가능에 가깝다. 바로 이 지점에서 Active Learning은 빛을 발한다. 학습 알고리즘이 스스로 '가장 배워야 할 가치가 있는' 데이터를 선택하여 전문가에게 라벨링을 요청하는 방식이기 때문이다. 목표는 최소한의 라벨링으로 최대한의 모델 성능을 달성하는 것이며, IBM, Microsoft, Google 등 여러 산업 현장에서 이미 그 효용성을 인정받아 활발히 사용되고 있다.
 |
| Motivation of Active Learning |
Active Learning의 작동 원리: 현명하게 질문하는 학습자 🤖
Active Learning은 마치 똑똑한 학생과 같다. 무작정 모든 것을 배우려 하기보다는, 현재 자신의 지식 상태를 파악하고 어떤 질문을 해야 가장 효과적으로 성장할 수 있을지 고민한다. 이 과정은 일반적으로 다음과 같은 순환적인 단계(round)를 거치며 진행된다.
 |
| Batch Active Learning |
- 초기 모델 학습: 현재까지 확보된 소수의 라벨링된 데이터 L을 사용하여 초기 모델(current model)을 학습시킨다.
- 정보성 평가: 학습된 현재 모델을 사용하여 라벨링되지 않은 대규모 데이터 풀 U에 있는 각 예제들의 '정보성(informativeness)'을 평가한다. 여기서 정보성이란, 해당 예제의 라벨을 알게 되었을 때 모델 성능 향상에 얼마나 기여할 수 있는지를 나타내는 척도이다.
- 쿼리 선택: 미리 정의된 '쿼리 선택 전략(query selection strategies)'에 따라 가장 정보성이 높다고 판단되는 예제(들)을 U에서 선택한다.
- 라벨 획득: 선택된 예제(들)에 대해 '라벨링 오라클(labeling oracle)' (일반적으로 인간 전문가)에게 라벨을 요청하여 획득한다.
- 데이터 통합 및 모델 재학습: 새로 라벨링된 예제(들)을 기존의 학습 데이터 L에 추가하고, 이렇게 업데이트된 전체 학습 데이터를 사용하여 모델을 다시 학습시킨다.
- 반복: 주어진 라벨 획득 예산(budget)이 소진되거나 모델 성능이 만족스러운 수준에 도달할 때까지 2~5단계를 반복한다.
이처럼 Active Learning은 현재 모델의 '지식'을 활용하여 다음 라벨링 대상을 능동적으로 결정함으로써, 무작위로 데이터를 선택하는 수동적인(passive) 학습 방식보다 훨씬 효율적으로 모델을 개선해 나간다.
Selective Sampling Active Learning (선택적 샘플링 액티브 러닝) 또는 Online AL (온라인 액티브 러닝)이라는 방식도 존재한다. 이는 라벨링되지 않은 예제들이 스트림 형태로 순차적으로 들어올 때, 각 예제에 대해 라벨을 즉시 요청할지 아니면 그냥 지나칠지를 실시간으로 결정하는 방식이다. 잘 설계된 Active Learning은 수동 학습이나 준지도 학습(SSL)보다 훨씬 적은 수의 라벨만으로도 우수한 성능의 분류기를 만들어낼 수 있을 것으로 기대된다.
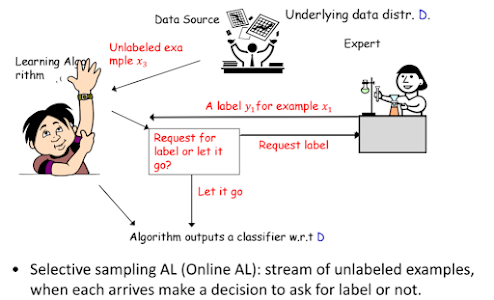 |
| Selective Sampling Active Learning |
핵심은 '정보성 높은 예제'의 선택: 다양한 쿼리 전략 🎯
Active Learning 알고리즘의 성능은 결국 '얼마나 정보성 높은 예제를 잘 선택하느냐'에 달려있다. 그렇다면 어떤 예제가 '정보성이 높은' 것일까? 이를 판단하기 위한 다양한 쿼리 선택 전략들이 존재하며, 주요 기법들은 다음과 같다.
1. 불확실성 샘플링 (Uncertainty Sampling)
가장 직관적이고 널리 사용되는 전략으로, 현재 모델이 가장 예측을 확신하지 못하는 예제를 선택하는 방식이다. 모델이 헷갈려 하는 데이터를 알려주면, 모델이 그 부분을 명확히 학습하여 경계를 더 잘 설정할 수 있을 것이라는 아이디어에 기반한다. 불확실성을 측정하는 방법에는 여러 가지가 있다.
-
초평면(Hyperplane)으로부터의 거리 기반:
Support Vector Machine (SVM)과 같은 모델에서 주로 사용된다. 현재 학습된 분류 경계(결정 경계, decision boundary)에 가장 가까이 있는 예제는 모델 입장에서 가장 아슬아슬하게 분류되는, 즉 불확실성이 높은 예제로 간주된다. 예를 들어, Tong & Koller (ICML 2000)의 Active SVM은 현재까지 라벨링된 모든 점들의 최대 마진(max-margin) 분리자 w로부터의 거리가 최소인, 즉 결정 경계에 가장 가까운 예제의 라벨을 요청한다.
Active SVM
-
확률론적 모델의 라벨 확률 기반:
모델이 각 클래스에 대한 예측 확률을 출력하는 경우, 이 확률값을 이용하여 불확실성을 정의할 수 있다.
Uncertainty Sampling - 최소 신뢰도 (Least Confident): 모델이 예측한 가장 가능성 높은 라벨 y∗에 대한 확률 \( P(y^{*}|x)\)가 가장 낮은 예제 x를 선택한다. 즉,
가장 유력한 정답조차도 확신이 낮은경우이다. 수학적으로는 \( argmin_{x} P(y^{*}|x)\) 또는 동등하게 \( argmin_{x} max_{y} P(y^{*}|x)\)로 표현할 수 있다. - 최소 마진 (Smallest Margin): 가장 확률이 높은 라벨 \(y^{*}_{1}\)과 두 번째로 확률이 높은 라벨 \(y^{*}_{2}\) 간의 확률 차이, 즉 가 가장 작은 예제 x를 선택한다. 두 후보 간의 차이가 작을수록 모델은 혼란스러워하는 상태라고 볼 수 있다.
- 라벨 엔트로피 (Label Entropy): 예측된 라벨 분포의 엔트로피(entropy)가 최대인 예제 x를 선택한다. 엔트로피는 정보 이론에서 불확실성의 척도로 사용되며, 모든 클래스에 대해 예측 확률이 유사하게 분산될수록 엔트로피는 높아진다. 라벨 Y에 대한 조건부 엔트로피는 \(H(Y|x)=-\sum P(y|x)logP(y|x)\)로 계산되며, 이 값이 가장 큰 예제를 선택한다.
고려사항: 불확실성 샘플링, 특히 초평면 거리 기반 방식은 효과적일 수 있지만, 탐욕적(greedy)인 접근 방식이기 때문에 샘플링 편향(sampling bias)에 취약할 수 있다는 점에 매우 신중해야 한다. 즉, 쿼리 전략에 의해 반복적으로 선택되는 예제들이 실제 데이터 분포를 제대로 대표하지 못하게 되어, 결국 전체 데이터에 대한 모델의 일반화 성능이 저하될 수 있다. 정보성이 높은 점을 선택하는 것도 중요하지만, 근본적으로는 실제 데이터 분포에서 무작위로 추출된 예제들에 대해서도 분류기가 좋은 성능을 발휘함을 보장해야 한다.
- 최소 신뢰도 (Least Confident): 모델이 예측한 가장 가능성 높은 라벨 y∗에 대한 확률 \( P(y^{*}|x)\)가 가장 낮은 예제 x를 선택한다. 즉,


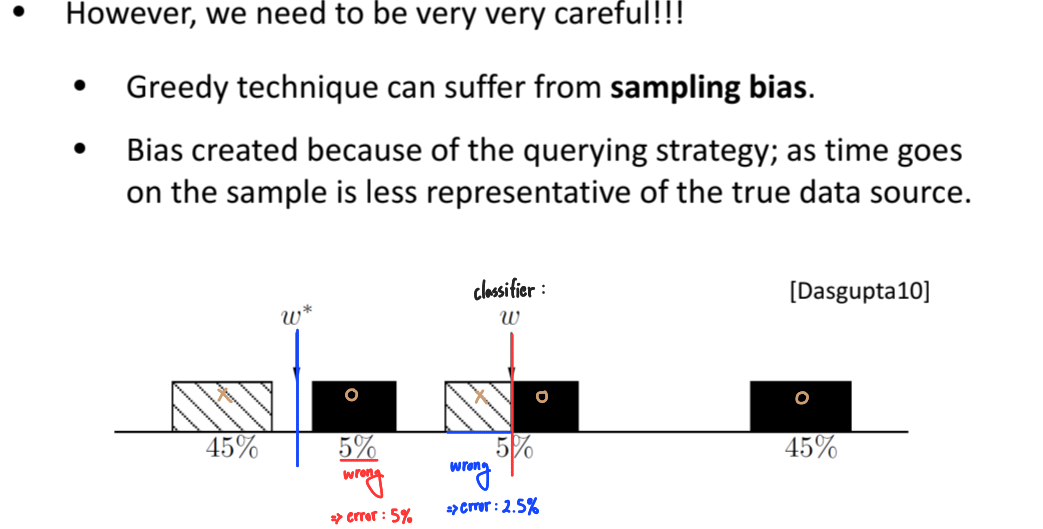 |
| Warning: Sampling Bias |
2. Query By Committee (QBC)
단일 모델의 판단에 의존하는 대신, 여러 모델로 구성된 '위원회(committee)' \(C=\begin{Bmatrix}\Theta^{(1)},...,\Theta^{(C)}\end{Bmatrix}\)를 활용하는 방식이다.
- 위원회의 각 모델 θ(i)은 현재까지 사용 가능한 라벨링된 데이터 L을 사용하여 학습된다. (예: 부트스트랩 샘플링된 데이터로 각기 다른 모델을 학습시키는 배깅(bagging) 방식, 또는 모델 파라미터 공간에서 서로 다른 모델을 샘플링하는 방식 등)
- 위원회 내 모든 모델들이 라벨링되지 않은 풀 U에 있는 각 예제 x에 대해 예측을 수행하고 '투표'를 한다.
- 위원회 내 모델들 간에 '불일치(disagreement)'가 가장 큰 예제를 다음 라벨링 대상으로 선택한다. 예를 들어, 어떤 예제에 대해 위원회 구성원들의 예측이 첨예하게 갈린다면, 그 예제는 현재 지식으로는 판단하기 어려운, 따라서 라벨을 알게 되면 유용한 정보를 줄 수 있는 예제로 간주된다. 불일치는 투표 엔트로피, 평균 KL 발산 등 다양한 방식으로 측정될 수 있다.
- 새로운 예제의 라벨이 획득되면, 위원회의 각 모델은 업데이트된 데이터로 재학습된다.
QBC 방식은 단일 모델의 편향된 시각에서 벗어나 다양한 '관점'을 통합하므로, 불확실성 샘플링에서 발생할 수 있는 샘플링 편향 문제를 완화하는 데 도움이 될 수 있다.
3. 기타 주요 전략
-
밀도 기반 샘플링 (Density-based Sampling):
단순히 모델이 불확실해하는 예제뿐만 아니라, 데이터 분포상에서 밀도가 높은 영역에 있는 예제를 선택하는 전략이다. 특정 예제의 정보가 주변의 많은 다른 예제들에게도 영향을 미칠 수 있다는 가정에 기반한다. 예를 들어, 라벨링되지 않은 가장 큰 클러스터의 중심(centroid)이나 대표점을 선택할 수 있다. 이 전략은 불확실성 샘플링과 결합하여 사용되기도 한다 (예: 정보성과 대표성을 모두 고려).
Density-based Sampling
-
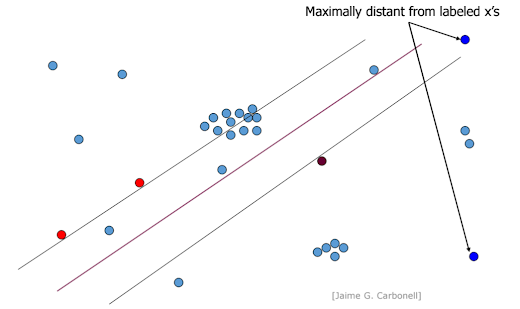
최대 다양성 샘플링 (Maximal Diversity Sampling):
새롭게 선택되는 예제가 이미 라벨링된 예제들과 최대한 다른 특성을 갖도록 하여 데이터의 다양성을 확보하려는 전략이다. 이는 모델이 아직 탐험하지 못한 데이터 공간의 영역을 학습하도록 유도한다.
Maximal Diversity Sampling -
앙상블 기반 샘플링 (Ensemble-based Sampling) / 혼합 전략 (Hybrid Strategies):
위에서 언급된 여러 전략들의 장점을 결합하려는 시도이다. 예를 들어, 불확실성과 다양성을 함께 고려하거나(Ensemble based Sampling), 밀도와 불확실성을 결합하여 사용하는 등 다양한 조합이 가능하다. 목표는 단일 전략의 단점을 보완하고 더 강건한(robust) 예제 선택을 하는 것이다.
Ensemble based Sampling


Active Learning의 중요성 및 효과 📈
Active Learning은 대규모 비라벨링 데이터 환경에서 라벨링 비용이라는 현실적인 병목 현상을 극복하고 효율적인 학습을 가능하게 하는 강력한 패러다임이다. 정보성이 높은 예제를 선별적으로 라벨링함으로써, 이론적으로나 실제적으로 라벨 복잡성(label complexity)에서 지수적인(exponential) 개선을 가져올 수 있다고 알려져 있다. 즉, 동일한 모델 성능을 달성하기 위해 필요한 라벨 데이터의 수를 크게 줄일 수 있다는 의미이다.
이미 이미지 분류(Image Categorization, 예: Kapoor et al. 2007), 이미지 분할(Image Segmentation, 예: Wang et al. 2012) 등 다양한 컴퓨터 비전 분야뿐만 아니라 자연어 처리, 신약 개발 등 광범위한 영역에서 Active Learning의 성공적인 적용 사례가 보고되고 있다.
 |
| Kapoor et al. 2007 |
 |
| Wang et al. 2012 |
고려사항 및 도전 과제 🤔
Active Learning은 매우 매력적인 기법이지만, 실제 적용 시 몇 가지 고려해야 할 점들이 있다.
- 샘플링 편향 (Sampling Bias): 앞서 언급했듯이, 특히 탐욕적인 불확실성 샘플링 전략은 샘플링 편향을 야기할 수 있다. 이를 완화하기 위해 QBC나 다양성 샘플링을 결합하는 등의 노력이 필요하다.
- 오라클의 비용 및 시간: 아무리 예제를 잘 선택한다 하더라도, 결국 인간 전문가의 라벨링은 시간과 비용을 수반한다. 오라클의 응답 시간, 피로도 등을 고려한 현실적인 시스템 설계가 중요하다.
- 적절한 쿼리 전략 선택: 데이터의 특성, 사용 가능한 모델, 문제의 종류에 따라 최적의 쿼리 전략은 달라질 수 있다. 어떤 전략이 항상 우월하다고 말하기는 어렵기 때문에, 문제에 맞는 전략을 선택하거나 여러 전략을 실험해보는 과정이 필요할 수 있다.
- 콜드 스타트 문제 (Cold Start Problem): 학습 초기에 라벨링된 데이터가 매우 적을 때는 모델 자체가 불안정하여 정보성을 제대로 평가하기 어려울 수 있다. 이 경우 초기에는 무작위 샘플링을 일부 사용하거나, 사전 학습된 모델을 활용하는 방안을 고려할 수 있다.
맺음말: 현명한 학습의 길을 찾아서 🚀
Active Learning은 제한된 자원 속에서 머신러닝 모델의 성능을 극대화하고자 하는 모든 이들에게 필수적으로 고려되어야 할 핵심 기법이다. 단순히 더 많은 데이터를 사용하는 것을 넘어, '어떤 데이터를 학습해야 하는가?' 라는 근본적인 질문에 답하려는 시도이기 때문이다.
불확실성 샘플링, QBC, 밀도 기반 샘플링 등 다양한 전략들은 결국 현재 모델의 '이해'를 바탕으로 다음에 '무엇을 배워야 할지'를 현명하게 결정하는 능력에 초점을 맞추고 있다. 물론 샘플링 편향과 같은 잠재적인 문제점들을 인지하고 이를 해결하려는 노력도 계속되고 있다.
이번 학습을 통해 Active Learning의 기본 원리와 다양한 쿼리 선택 전략, 그리고 그 중요성에 대해 깊이 이해할 수 있었다. 앞으로 실제 문제에 직면했을 때, 이러한 지식을 바탕으로 데이터 라벨링의 효율성을 높이고 모델 성능을 한 단계 끌어올릴 수 있기를 기대한다. Active Learning은 단순히 기술적인 접근 방식을 넘어, '효율적인 학습이란 무엇인가'에 대한 깊이 있는 고민을 안겨주는 매력적인 분야임에 틀림없다.
추천글:
[기계학습개론] Supervised learning technique - Support Vector Machine
[기계학습개론] Unsupervised learning technique - Clustering methods(Hierarchical clustering, K-means clustering, Gaussian Mixture Model, Spectral clustering)