준지도 학습 (Semi-Supervised Learning, SSL): 제한된 레이블 속에서 가능성을 발견하다
최근 딥러닝 모델들이 보여주는 눈부신 성과는 대부분 방대한 양의 레이블링된 데이터(Labeled Data) 덕분이다. 하지만 현실 세계에서 이처럼 잘 정제된 데이터를 대규모로 확보하는 것은 엄청난 도전 과제이다. 레이블링 작업은 시간, 비용, 전문 지식을 요구하는 고된 과정이기 때문이다. 어떤 경우에는 특정 분야 전문가의 판단이나 특수 장비까지 필요하다.
이러한 배경에서, 준지도 학습(Semi-Supervised Learning, SSL)은 한 줄기 빛과 같은 해법을 제시한다. SSL은 소수의 레이블링된 데이터와 다수의 레이블링되지 않은 데이터(Unlabeled Data)를 함께 활용하여, 오직 레이블링된 데이터만 사용했을 때보다 더 우수한 학습기를 만들고자 하는 패러다임이다. 말 그대로 지도 학습과 비지도 학습의 경계에서 두 방법의 장점을 취하려는 시도라고 볼 수 있다. 오늘 이 시간에는 SSL의 핵심 아이디어부터 주요 방법론에 대해 알아보고자 한다.
1. 준지도 학습(SSL)이란 무엇인가? 기본 아이디어 및 필요성
SSL의 핵심 아이디어는 레이블링되지 않은 데이터가 데이터의 전반적인 분포나 구조에 대한 유용한 정보를 담고 있다는 믿음에서 출발한다. 비록 각 데이터 포인트의 정확한 클래스를 알려주진 않지만, 데이터들이 자연스럽게 어떻게 군집을 이루는지, 어떤 저차원 매니폴드(Manifold) 위에 놓여 있는지 등에 대한 귀중한 단서를 제공한다. 이 정보가 소수의 레이블링된 데이터가 제공하는 명시적인 클래스 정보와 결합될 때, 모델은 데이터 공간을 더욱 효과적으로 이해하고 일반화 성능을 크게 향상시킬 수 있다.
간단한 예를 들어보자. 서로 다른 클래스에 속하는 두 개의 레이블링된 데이터 포인트만 있다고 가정하자. 이 두 점만으로는 명확한 결정 경계(Decision Boundary)를 설정하기 매우 어렵다.
 |
| Only two labeled data |
하지만 여기에 수많은 레이블링되지 않은 데이터 포인트들이 추가된다면 어떨까? 이 데이터들이 특정 영역에 밀집되어 자연스러운 군집을 형성하는 패턴을 보인다면, 우리는 이 군집 패턴을 활용하여 두 레이블링된 데이터가 속한 클래스를 구분하는 결정 경계를 훨씬 더 합리적이고 정교하게 설정할 수 있다. 이것이 바로 레이블링되지 않은 데이터를 '보는 것'의 힘이다.
 |
| with unlabeled data |
SSL이 절실히 필요한 이유는 명확하다: 레이블링된 데이터 확보의 극심한 어려움 때문이다. 웹 크롤링이나 센서 데이터 수집 등을 통해 레이블링되지 않은 데이터는 비교적 쉽게 대량으로 얻을 수 있지만, 여기에 정확한 레이블을 다는 작업은 막대한 자원을 소모한다. 따라서 풍부한 레이블링되지 않은 데이터를 적극적으로 활용하는 SSL은 현실 세계의 문제를 해결하는 데 있어 매우 실용적이고 강력한 접근 방식이 된다.
 |
| Why do we need SSL? |
2. SSL의 주요 방법론 대분류 🗺️
SSL 연구는 다양한 철학과 접근 방식을 통해 발전해왔으며, 그 방법론들은 크게 다음과 같은 네 가지 범주로 나누어 볼 수 있다:
- 자기 학습 (Self-training Method)
- 생성 모델 기반 (Generative Model based Method)
- 마진 기반 (Margin based Method)
- 그래프 기반 (Graph based Method)
이제 각 방법론의 핵심 원리와 장단점을 하나씩 자세히 파헤쳐 보자.
3. 자기 학습 (Self-training): 스스로 답을 찾아가는 모델 🧠
세부 아이디어
자기 학습(Self-training)은 SSL 방법론 중 가장 직관적이고 단순한 형태 중 하나이다. 핵심 가정은 "모델 자신이 높은 확신을 가지고 내린 예측은 옳을 가능성이 높다"는 것이다.
알고리즘은 다음과 같은 단계로 진행된다:
- 먼저, 소수의 레이블링된 데이터 만을 사용하여 초기 분류기 \(f\)를 학습시킨다.
- 학습된 분류기 \(f\)를 레이블링되지 않은 데이터 \(x\in X_{u}\)에 적용하여 예측값 \(f(x)\) (또는 유사 레이블, Pseudo-label)을 얻는다.
- 이 예측 결과 중 가장 확신도가 높은 일부 를 새로운 레이블링된 데이터로 간주하여 기존 학습 데이터셋에 추가한다. (변형: 모든 예측 결과를 추가하거나, 확신도에 비례하는 가중치를 부여하여 추가할 수도 있다.)
- 확장된 학습 데이터셋으로 분류기 \(f\)를 재학습시킨다.
- 위 2~4단계를 반복하여 점진적으로 분류기 성능을 개선한다.
사례
자기 학습은 그 단순함 덕분에 다양한 분류 문제, 특히 자연어 처리(NLP) 분야에서 실제 태스크에 빈번하게 활용된다. 예를 들어, 문장 감성 분석 모델을 학습시킬 때, 소수의 레이블링된 문장으로 초기 모델을 만든 후, 대량의 레이블링되지 않은 문장에 대해 모델의 예측(예: 긍정/부정 확률)이 특정 임계값을 넘으면 해당 문장과 예측된 레이블을 학습 데이터에 추가하여 모델 성능을 점진적으로 향상시킬 수 있다.
장단점
- 장점:
- 가장 단순한 SSL 방법론으로 이해하고 구현하기 쉽다.
- 기존의 어떤 분류기에도 적용할 수 있는 유연한 '래퍼(wrapper)' 방식이다.
- NLP와 같은 실제 응용 분야에서 자주 사용되며 효과를 보이기도 한다.
- 단점:
- 학습 초기에 발생한 잘못된 예측이 스스로 강화되어 누적될 경우, 모델 성능이 오히려 저하될 수 있다 (Early mistakes can reinforce themselves). 이 점이 자기 학습의 가장 큰 아킬레스건이다.
- 알고리즘의 수렴성에 대한 이론적 분석이 다소 부족한 편이다.
4. 생성 모델 기반 (Generative Model based): 데이터의 숨겨진 분포를 그리다 🎨
세부 아이디어
생성 모델(Generative Model) 기반 SSL은 데이터가 특정 확률 분포(예: 가우시안 혼합 모델, Gaussian Mixture Model, GMM)로부터 생성되었다고 가정하고, 이 모델의 파라미터 theta를 학습하는 데 초점을 맞춘다.
레이블링된 데이터만 있다면, 모델 파라미터 theta에 대한 최대우도 추정(Maximum Likelihood Estimation, MLE)은 비교적 간단하다 (예: 각 클래스별 데이터의 빈도, 표본 평균/공분산 계산).
 |
| All of the data are labeled |
하지만 레이블링되지 않은 데이터 \(X_{u}\)까지 포함하게 되면, \(X_{u}\)의 각 데이터 포인트에 대한 실제 클래스 레이블이 잠재 변수(Hidden Variable)가 되어 MLE를 직접 계산하기 어려워진다.
 |
| with unlabeled data |
 |
| Summary |
이때, EM (Expectation-Maximization) 알고리즘과 같은 기법을 사용하여 관측된 데이터 (\(X_{l}\),\(Y_{l}\))과 잠재 변수를 포함하는 \(X_{u}\) 전체에 대한 우도 \(p(X_{l},Y_{l},X_{u}|theta)\)를 최대화하는 모델 파라미터 theta의 지역 최적값(Local Optimum)을 찾을 수 있다.
 |
| EM algorithm for SSL |
이 접근법의 핵심은 레이블링되지 않은 데이터가 모델 파라미터 추정에 직접적으로 영향을 미치고, 결과적으로 데이터 분포에 더 잘 부합하는 결정 경계를 형성하는 데 기여한다는 점이다. 예를 들어 GMM을 사용하는 이진 분류에서, 레이블 없는 데이터는 각 가우시안 성분의 위치, 모양, 크기를 더 정확하게 추정하도록 도와, 두 클래스를 구분하는 경계가 데이터의 실제 밀집 영역을 잘 반영하도록 유도한다.
사례
GMM을 이용한 이진 분류 문제가 대표적인 예시이다. 예를 들어, 고양이와 개 이미지 데이터에서 각 클래스의 특징 분포를 GMM으로 모델링한다고 가정하자. 소수의 레이블링된 고양이/개 이미지와 다수의 레이블링되지 않은 동물 이미지를 함께 사용하여 각 클래스에 해당하는 GMM 컴포넌트들의 파라미터(평균, 공분산 등)를 더 정확하게 추정함으로써, 새로운 이미지가 고양이인지 개인지 분류하는 성능을 향상시킬 수 있다.
장단점
- 장점:
- 확률론적 프레임워크가 명확하고 이론적으로 잘 연구되어 있다.
- 만약 가정한 생성 모델이 실제 데이터 분포와 잘 부합한다면 (if the model is close to correct), 매우 효과적인 성능을 보일 수 있다.
- 단점:
- 모델 가정의 정확성을 검증하기 어려운 경우가 많으며, 만약 가정한 생성 모델이 실제 데이터 분포와 크게 다르다면(if generative model is wrong), 레이블링되지 않은 데이터가 오히려 모델 성능을 저해할 수도 있다.
- EM 알고리즘은 지역 최적값(Local Optima)에 수렴하는 문제가 있다.
5. 마진 기반 (Margin based): 결정 경계의 여백을 탐색하다 📐
세부 아이디어
마진 기반(Margin-based) SSL은 주로 서포트 벡터 머신(Support Vector Machine, SVM)의 핵심 아이디어인 마진 최대화 개념을 SSL 환경으로 확장하는 방식으로 발전했다. 표준 SVM은 레이블링된 데이터만을 사용하여 두 클래스 간의 마진(Margin)을 최대화하는 결정 경계를 찾는다.
마진 기반 SSL의 대표적인 예인 Transductive SVM (TSVM)은 레이블링된 데이터와 레이블링되지 않은 데이터 \(X_{u}\)를 모두 사용하여 학습한다. TSVM의 목표는 레이블링된 데이터는 정확히 분류하면서, 동시에 레이블링되지 않은 데이터에 대해서도 (아직 알 수 없는) 잠재적인 레이블을 할당했을 때 전체적인 마진이 최대화되도록 결정 경계를 찾는 것이다.
 |
| Transductive SVM |
직관적으로, TSVM은 레이블링되지 않은 데이터 포인트들이 결정 경계 근처의 저밀도 영역(Low-density regions)에 위치하도록 유도한다. 즉, 결정 경계가 레이블링되지 않은 데이터 포인트들을 가급적 피해서, 데이터가 밀집된 영역의 한가운데를 지나가지 않도록 조정된다. 이 과정은 레이블링되지 않은 데이터의 가능한 모든 레이블 할당 조합을 고려해야 하므로, 최적화 문제가 매우 복잡해진다. 실제로 이 문제는 NP-hard로 알려져 있어 전역 최적해를 찾는 것이 매우 어렵다. 따라서 실제 구현에서는 근사 알고리즘이나 휴리스틱한 접근 방식이 사용된다. 예를 들어, 초기 분류기로 레이블링되지 않은 데이터에 임시 레이블을 할당하고 SVM을 학습한 후, 레이블 할당을 조금씩 변경하며 마진이 커지는 방향으로 반복적으로 최적화하는 방식 등이 있다.
 |
| TSVM formula |
사례
Transductive SVM (TSVM) 자체가 마진 기반 SSL의 핵심적인 사례이다. TSVM은 텍스트 분류, 이미지 분류 등 전통적인 SVM이 효과를 보였던 다양한 분야에서 레이블링되지 않은 데이터를 추가로 활용하여 분류 성능을 개선하는 데 사용될 수 있다.
장단점
- 장점:
- SVM이 잘 작동하는 모든 문제 영역에 적용 가능하다.
- 결정 경계 주변의 데이터 분포를 고려하므로, 밀도 기반의 클러스터 가정을 잘 활용한다.
- 단점:
- 최적화 문제가 매우 어렵다 (NP-hard). 효율적인 해법을 찾기 위한 연구가 계속되고 있지만, 여전히 도전적인 과제이다.
- 잘못된 지역 최적값(Bad local optima)에 빠질 위험이 크다.
- 대규모 데이터셋에 적용하기에는 계산 비용이 높을 수 있다.
6. 그래프 기반 (Graph based): 데이터 간의 연결고리를 따라가다 🕸️
세부 아이디어
그래프 기반(Graph-based) SSL은 데이터 포인트 간의 유사성을 그래프(Graph) 구조로 모델링하여 레이블 정보를 전파(Propagate)하는 방식이다. 핵심 직관은 "유사한 데이터 포인트는 유사한 레이블을 가질 것이다"라는 것이다.
- 그래프 구축: 전체 데이터셋(레이블링된 데이터 L과 레이블링되지 않은 데이터 U)의 각 인스턴스를 그래프의 노드(Node)로 표현한다. 노드 간의 엣지(Edge)는 데이터 포인트 간의 지역적 유사성(Local Similarity)을 나타내며, 이는 보통 N⨉N 대칭 가중치 행렬 W로 표현된다 (N은 전체 데이터 수). \(W_{ij}\)는 데이터 포인트 i와 j 사이의 유사도 값이다 (예: 거리 기반, 커널 기반 유사도).
Graph based SSL - 레이블 전파: 그래프가 구축되면, 레이블링된 데이터 노드로부터 시작하여 그래프의 엣지를 따라 레이블 정보가 레이블링되지 않은 데이터 노드로 "전파"된다. 이 전파 과정은 다양한 방식으로 모델링될 수 있다. 예를 들어, 각 노드가 이웃 노드로부터 레이블 정보를 반복적으로 받아 자신의 레이블을 갱신하는 레이블 전파 알고리즘(Label Propagation Algorithm, LPA)이 대표적이다. 또는, 그래프 라플라시안(Graph Laplacian)을 사용하여 전체 그래프에서 레이블이 부드럽게(Smoothly) 변하도록 하는 최적화 문제를 풀 수도 있다. 목표는 그래프 구조를 고려했을 때, 레이블링된 데이터의 제약을 만족시키면서 전체 데이터셋에 걸쳐 레이블 할당이 일관성을 갖도록 하는 것이다.
Label Propagation Algorithm
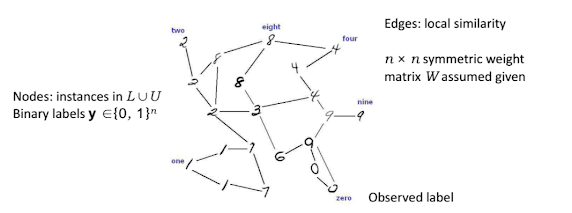

그래프 라플라시안의 (유사) 역행렬은 커널 행렬로 해석될 수 있어, 그래프 기반 방법이 다른 커널 기반 학습 방법과 깊은 연관성을 가짐을 시사한다. 또한, 방향성 그래프(Directed Graphs)로도 확장이 가능하다.
 |
| Labeled example |
사례
Label Propagation Algorithm 및 그 변형들이 대표적이다. 이미지 데이터셋에서 각 이미지를 노드로, 이미지 간 시각적 유사도를 엣지 가중치로 하는 그래프를 만든 후, 소수의 레이블링된 이미지를 통해 레이블 정보를 다수의 레이블링되지 않은 이미지로 전파시켜 분류하는 데 활용될 수 있다. 소셜 네트워크에서 사용자 간의 친구 관계를 그래프로 모델링하고, 일부 사용자의 특성(예: 특정 제품 선호도)을 나머지 사용자들에게 전파하여 예측하는 문제에도 응용 가능하다.
장단점
- 장점:
- 수학적 프레임워크가 비교적 명확하며, 특히 매니폴드 가정(Manifold Assumption - 데이터가 저차원 매니폴드 상에 놓여있다는 가정)을 잘 활용한다.
- 구축된 그래프가 실제 데이터의 내재적 구조를 잘 반영한다면 (if the graph happens to fit the task), 매우 뛰어난 성능을 보일 수 있다.
- 단점:
- 그래프의 품질에 성능이 매우 민감하다. 어떤 노드들을 연결할지(이웃의 정의), 엣지 가중치를 어떻게 설정할지 등 그래프 구축 방식에 따라 결과가 크게 달라질 수 있다. 잘못된 그래프는 오히려 성능을 저하시킨다.
- 대규모 데이터셋에서는 그래프를 메모리에 저장하고 연산하는 비용이 클 수 있다.
7. 결론: 레이블 너머의 지혜를 향하여 🌟
준지도 학습(Semi-Supervised Learning)은 레이블링된 데이터의 부족이라는 현실적인 제약을 극복하고, 풍부한 레이블링되지 않은 데이터 속에 숨겨진 무한한 가능성을 탐색하려는 매력적인 패러다임이다. 레이블 없는 데이터가 제공하는 데이터의 분포 및 구조 정보를 효과적으로 활용함으로써, SSL은 순수 지도 학습의 성능을 뛰어넘는 강력한 모델을 구축할 수 있는 잠재력을 지닌다.
오늘 살펴본 자기 학습, 생성 모델 기반, 마진 기반, 그래프 기반 방법론들은 각기 다른 철학과 수학적 도구를 사용하여 이 목표에 도전한다. 자기 학습은 단순함과 유연성을, 생성 모델은 확률적 해석의 명확성을, 마진 기반 방법은 결정 경계 최적화의 정교함을, 그래프 기반 방법은 데이터 간 관계 구조 활용의 직관성을 각각 장점으로 내세운다. 하지만 동시에 각 방법론은 오류 전파, 모델 가정의 정확성, 최적화의 어려움, 그래프 품질 의존성 등 극복해야 할 과제들도 안고 있다.
어떤 SSL 방법론을 선택할지는 당면한 문제의 특성, 데이터의 성격, 그리고 우리가 가진 사전 지식에 따라 신중하게 결정되어야 한다. 각 방법론의 이론적 깊이와 실용적 장단점을 이해하는 것은, 앞으로 우리가 더욱 지능적인 시스템을 설계하고 구현하는 데 든든한 밑거름이 될 것이다. 레이블의 한계를 넘어 데이터의 진정한 가치를 끌어내는 SSL 연구의 여정은 앞으로도 계속될 것이며, 더욱 새롭고 강력한 아이디어들이 우리를 기다리고 있을 것이라 확신한다.
추천글:
[기계학습개론] Supervised learning technique - Support Vector Machine
[기계학습개론] Unsupervised learning technique - Clustering methods(Hierarchical clustering, K-means clustering, Gaussian Mixture Model, Spectral clustering)[기계학습개론] Collaborative Filtering (CF) - KNN vs Matrix Factorization
