그래프 알고리즘 I: 깊이 우선 탐색 (DFS)
그래프는 정점(vertex)과 간선(edge)으로 이루어진 자료 구조다. 정점(vertex)은 데이터를 나타내고, 간선(edge)은 정점 간의 관계를 나타낸다. 그래프는 다양한 문제를 모델링하는 데 사용될 수 있으며, 소셜 네트워크, 지도, 웹 페이지 연결 등을 표현하는 데 유용하다. 자세한 내용은 자료구조 시간에 다뤘으므로 참고하도록 하자.
그래프 표현 방식
그래프는 크게 두 가지 방식으로 표현할 수 있다.
- 인접 행렬 (Adjacency Matrix): 2차원 배열을 사용하여 정점 간의 연결 관계를 표현한다. 행렬의 각 요소는 두 정점 사이에 간선이 존재하는지 여부를 나타낸다.

adjacency matrix - 연결 리스트 (Linked List): 각 정점에 대해 연결된 정점들의 리스트를 저장한다.

linked list


인접 행렬과 연결 리스트의 시간 복잡도 분석
두 표현 방식은 각각 장단점을 가지고 있다. 인접 행렬은 간선 존재 여부를 확인하는 데 \(O(1) \) 시간이 걸리지만, 모든 간선을 확인하는 데 \(O(n^{2}) \) 시간이 걸린다. 반면 연결 리스트는 간선 존재 여부를 확인하는 데 \(O(deg(v)) \) 시간(이때 deg는 degree 즉 v에서 나가는 간선의 수)이 걸리지만, 모든 간선을 확인하는 데 \(O(n+m) \) 시간이 걸린다. 여기서 n은 정점의 수, m은 간선의 수, deg(v)는 정점 v의 차수(degree)를 의미한다.
 |
| left : adjacency matrix, right : linked list |
따라서 간선이 많은 밀집 그래프(Dense Graph)의 경우 인접 행렬이 유리하며, 간선이 적은 희소 그래프(Sparse Graph)의 경우 연결 리스트가 유리하다.
깊이 우선 탐색 (DFS)
깊이 우선 탐색 (Depth First Search, DFS)은 그래프를 탐색하는 알고리즘 중 하나다. DFS는 시작 정점에서부터 가능한 깊이까지 탐색을 진행하고, 더 이상 진행할 수 없으면 이전 정점으로 돌아와 다른 경로를 탐색하는 방식으로 동작한다.
DFS의 작동 방식
DFS는 각 정점을 다음 세 가지 상태로 분류한다.
- Unvisited: 아직 탐색하지 않은 정점
- In Progress: 현재 탐색 중인 정점
- All Done: 탐색이 완료된 정점
DFS는 시작 정점을 '진행 중'으로 표시하고, 인접한 정점 중 '방문하지 않은' 정점을 재귀적으로 방문한다. 더 이상 방문할 정점이 없으면 현재 정점을 '모두 완료'로 표시하고 이전 정점으로 돌아간다.
 |
| Depth First Search algorithm |
DFS의 의사 코드 (Pseudocode)
DFS(w, currentTime):
w.startTime = currentTime
currentTime++
Mark w as in progress
for v in w.neighbors:
if v is unvisited:
currentTime = DFS(v, currentTime)
currentTime++
w.finishTime = currentTime
Mark w as all done
return currentTime이 때 DFS는 각 간선을 오직 한 번 방문하기 때문에, 실행 시간은 \(O(m) \)이다. 여기서 m은 간선의 수이다. (linked list로 구현한 DFS를 가정)
그리고 모든 정점에 대하여 DFS를 호출하면, N개의 정점을 탐색해야 하므로, 실행 시간은 \(O(n + m) \)이 된다. 참고로 adjacency matrix로 구현하면 실행 시간은 \(O(n^{2}) \)이다.
 |
| DFS to explore the whole thing |
이를 이용해 DFS를 연결 요소(Connected Component)를 찾거나 in-order traversal, exact traversal을 할 수 있다.
DFS의 특징: 트리와 유사한 구조
DFS는 탐색 과정에서 각 정점의 방문 시간과 완료 시간을 기록한다. 이러한 정보를 이용하면 DFS 트리(DFS Tree)를 구성할 수 있다. DFS 트리는 DFS 탐색 과정을 트리 형태로 나타낸 것으로, 루트는 시작 정점이고, 각 정점의 자식은 DFS 탐색 순서대로 방문한 정점들이다. DFS 트리는 그래프의 구조를 파악하고, 사이클(cycle)을 찾는 데 유용하게 사용된다.
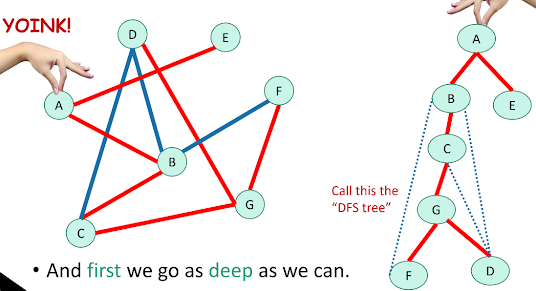 |
| DFS tree |
위상 정렬 (Topological Ordering)
DFS의 활용 사례로는 위상 정렬이 있다. 위상 정렬은 방향 그래프(Directed Graph)의 정점들을 순서대로 나열하는 것으로, 모든 간선 (u, v)에 대해 정점 u가 정점 v보다 앞에 오도록 하는 것이다. 쉽게 말해, 우선순위에 맞춰 정렬하는 것을 말한다. 위상 정렬은 선수 과목 찾기, 작업 스케줄링, 컴파일러 의존성 분석 등에 사용된다.
 |
| Prerequisite subjects |
위와 같은 Graph를 방향 비순환 그래프 (Directed Acyclic Graph, DAG)라고 하는데, 이는 사이클이 없는, 즉 되돌아오지 않는 방향 그래프이다. 위상 정렬은 DAG에서만 가능하다.
위상 정렬의 원리
앞서 우리는 DFS의 pesudocode에서 time을 기록한 적이 있다. 위상 정렬은 Finish time의 아이디어를 이용해 구현된다. DFS 탐색을 수행하면서 각 정점의 완료 시간을 기록하고, 완료 시간이 늦은 정점부터 출력하면 위상 정렬 순서가 된다.
 |
| time recording in DFS |
위의 예시에서 finish time이 클수록 먼저 가장 우선시된다는 점을 파악할 수 있다.
이를 보다 엄밀히 증명해보면 다음과 같다.
 |
| parentheses theorem |
- v는 w의 자손인 경우 : DFS의 작동 방식에 의해 DFS tree에서 가장 위에 있는 node가 가장 먼저 실행되고, 가장 마지막으로 끝나므로 finish time은 v < w이다.
- v가 w의 자손이 아닌 경우 : DFS의 작동 방식에 의해 v가 먼저 실행 및 종료되고, w가 나중에 실행 및 종료되므로 finish time은 v < w이다.
마치며
이번 포스팅에서는 그래프 알고리즘의 기본 개념과 깊이 우선 탐색 (DFS)에 대해 알아보았다. DFS는 그래프 탐색, 연결 요소 찾기, 위상 정렬 등 다양한 문제를 해결하는 데 사용되는 중요한 알고리즘이다. 다음 시간에는 또 다른 탐색 알고리즘인 너비 우선 탐색 (BFS)에 대해 알아보고자 한다.
추천글:
[알고리즘] hash table의 worst case를 극복하는, Self-Balancing Binary Search Tree(Red-Black Tree)
(https://hyeondev.blogspot.com/2024/10/hash-table-worst-case-self-balancing.html)
